
By now, we know which side we stand, but at the foot of the cross it is not so simple. Proximity is always a good thing, but it doesn’t mean that you are good, just because you are there. Three people take their places, looking up towards Jesus. Their attitudes are completely different, but abundantly clear, the result of the Master of Delft’s wonderful capacity to capture body language and expression. As more than one of you has pointed out, this painting verges on the cartoonish fairly often – but the more exaggerated someone appears, the less we should respect them. If we remember that a civilised member of society would conduct themselves with a measured demeanour, any exaggerated gesture – excessive pointing (which is rude anyway), waving, or grimacing would not be seen as gentlemanly or ladylike. The excesses of extreme grief could be forgiven, perhaps.
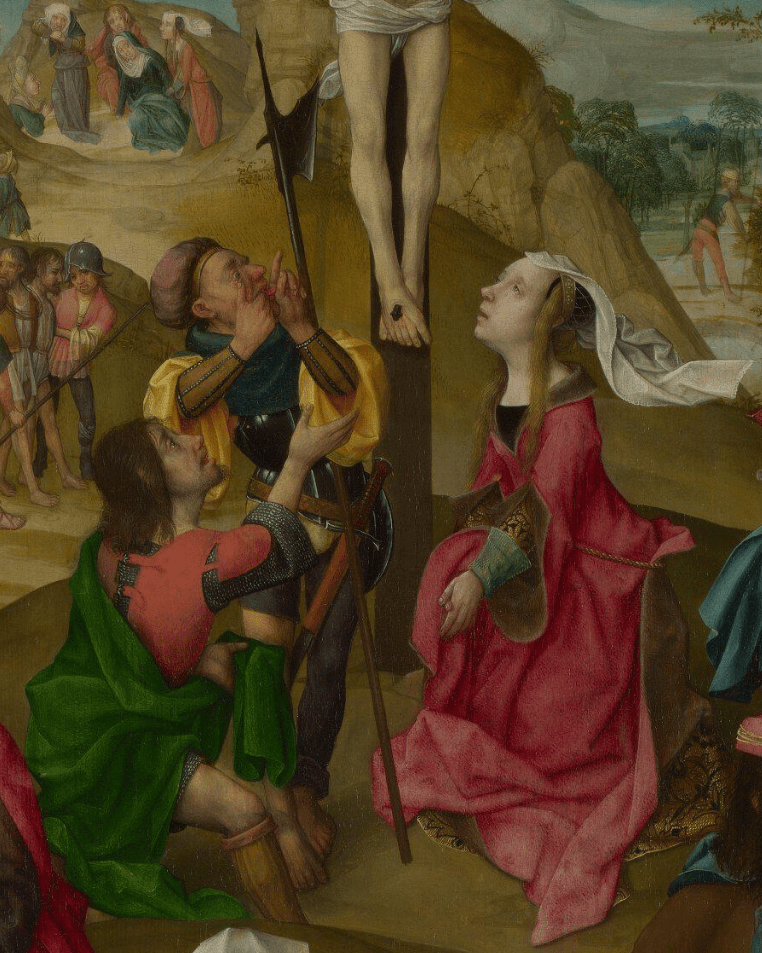
This detail embodies to perfection three completely different responses to exactly the same situation. Two are biblical in origin, the third, part of church lore. The last of these is the appearance and response of Mary Magdalene. We have seen her before, in Lent 24, and indeed, we can see the trepidacious supporters at the top left of this detail. The Magdalene adopts the same posture, to the extent that her headdress even enjoys the same breeze. Inevitably there is more detail, notably in the rich gold brocade of her dress, revealed by the belt, which holds up the hem of her red overdress, and by the latter’s full, slashed sleeves. She links her thumbs in much the same way as the donor (Lent 25) – I don’t know if this is a mannerism of the artist, or contemporary religious practice. Maybe I should look up De Modo Orandi – ‘About the Ways of Praying’ – although as this was a 13th century text about St Dominic’s prayer regime it is probably not relevant here.
On the other side are two soldiers – one has fallen down onto his left knee, and looks up in awe with a longing gesture, the other bends backwards, hip thrust out, pointing and sticking his tongue out just like the mocking man from Lent 8 – a standard form of disrespect, it would seem. I think they are illustrations of specific texts. The kneeling man is undoubtedly the ‘centurion’ mentioned by Matthew (27:54), Mark (15:29) and Luke (23:47). This is Mark:
And when the centurion, which stood over against him, saw that he so cried out, and gave up the ghost, he said, Truly this man was the Son of God.
That newly found belief is apparent in every limb of his body, the tilt of his head, and the open, breathing mouth – he is ‘inspired’, or ‘breathed into’. The other soldier, though, is his opposite – all ineffectual menace and mockery. I think this characterisation is derived from Matthew 27:39-40,
And they that passed by reviled him, wagging their heads, And saying, Thou that destroyest the temple, and buildest it in three days, save thyself. If thou be the Son of God, come down from the cross.
He is holding a halberd – a medieval weapon that looks like a cross between an axe and a spear. Of course, there was a soldier present with a spear, as we know from John 19:34,
But one of the soldiers with a spear pierced his side, and forthwith came there out blood and water.
From the detail we cannot tell if this has happened yet – but I do not think that this disreputable man is the one to do it. In the apocryphal Gospel of Nicodemus, which I mentioned yesterday, the soldier responsible for piercing Christ’s side is named as Longinus – a Latinised form of the Greek word for ‘lance’ – and is said to be the very centurion who utters the words of belief from Mark 15:29 that I quoted above. He was said to have converted to Christianity, and was eventually canonised as a saint. Before the reforms of the Roman Catholic calendar in 1969, his feast day was 15 March. I’m sorry, we failed to celebrate last week, so we will have to wait until 16 October, which is the ‘new’ official date. His journeys took him as far as Mantua (according to the Mantuans), where he left a relic of the Holy Blood, and the head of the lance somehow made its way to St Peter’s, where it has been since the 15th Century. Bernini carved a remarkable sculpture of Longinus for the crossing of the basilica, 4.4 m high, and just as wide, a result of his baroque gesture of astonishment. I do believe that this is him kneeling, although, as yet, he has no lance.

The mocking soldier is truly grotesque when seen up close, his eyes bulging, with the thumb apparently pulling down an eyelid (when done with the forefinger, for the Italians this is a gesture warning you to keep an eye on someone – I don’t know about the Netherlands in the 16th Century, though). It has that same sense of the obscene that we saw back in Lent 8, a finger thrust into the grimacing mouth, and that nasty combination of finger and tongue. The echo of the heavy brow and pointed nose doesn’t help either. Meanwhile Mary Magdalene is all pale and repentant, tearful and humble. Her mouth is at precisely the right level to kiss Christ’s feet, the part of his body with which she had been associated since her first putative appearance in the bible.

She is first mentioned by name in Luke 8:2,
And certain women, which had been healed of evil spirits and infirmities, Mary called Magdalene, out of whom went seven devils…
Immediately before this, in Luke 7:37-38, Christ is at dinner, and the following happens:
And, behold, a woman in the city, which was a sinner, when she knew that Jesus sat at meat in the Pharisee’s house, brought an alabaster box of ointment, And stood at his feet behind him weeping, and began to wash his feet with tears, and did wipe them with the hairs of her head, and kissed his feet, and anointed them with the ointment.
There is nothing to say that this ‘sinner’ was Mary Magdalene, but in 591 Pope Gregory I said that they – together with Mary, sister of Martha and Lazarus – were one and the same, and thus they remained until 1969. For 1378 years Mary Magdalene was seen as a penitent sinner, with no biblical authority whatsoever (although there are other circumstantial reasons for eliding the three women, but I will leave that for another day). As Luke’s ‘sinner’ wept, washed ‘his feet with tears, and did wipe them with the hairs of her head, and kissed his feet, and anointed them with the ointment,’ Mary Magdalene has been associated with tearfulness, ointment, hair, and Christ’s feet ever since – hence the position of her head in this detail. She has no ointment just now, but hair and tears are flowing. She was, indeed, maudlin – the same word as Magdalene – and yes, that’s why Oxbridge alumni can’t pronounce the name as it is spelt. You will hear speak of Maudlin College in both Oxford and Cambridge. Miserable bunch, as I remember! Still – like her, things are now looking up for us in our current woes, and tomorrow that is precisely what we shall do: look up.

As I understand it (sorry, not a Catholic myself) the liturgically correct form of prayer (“hands folded”) is with the palms held together, fingers extended, and the right thumb over the left to make the sign of the cross. I suspect it has been thus for a very long time. Symbolically, this can be seen as a feudal gesture of submission and fealty, with God’s invisible hands closed over the hands of the person praying, in much the same way as a bishop closes his hands over those of an ordinand.
There is a lance or spear further to the right – the sharp end in Lent 10 and 11, and the butt in Lent 26 – but its snub-nosed bearer looks too ugly to be Longinus. If the kneeling man is Longinus, he must have used the spear already and discarded it, as no doubt we will see shortly.
LikeLike
Thank you – I’m not a Catholic either, and haven’t been a church service of any denomination for more time than I can remember – but I was certainly never told how to hold my hands while praying, and this, like many other things, is one of the things I have not noticed in a painting before.
As for Longinus, you could well be right – or the Master of Delft/Premonstratensians weren’t buying into those ideas anyway. However busy this painting is, there are still so many things not there – casting lots over the seamless robe, for example…
LikeLike
The crossing of the thumbs was taught in the preparation of Catholic children for their First Holy Communion. Some adult worshipers still pray in this way.
LikeLike
Thank you!
LikeLike
As an ex Catholic I cannot remember being told how to hold my hands during prayer. Worried that I may have done this incorrectly in the past I googled the liturgical instructions to discover that the right thumb should be over the left. Amusingly the recent Popes do not follow this rule so I hope I’m in the clear!
I couldn’t find anything regarding thumbs before the 19th century. Perhaps our donor was more pedantic than current Popes?
LikeLike
I don’t know – several Catholics have reported being taught to do this, but that doesn’t mean it was common in the past. Maybe our Premonstratensian patron had strong convictions about it, though.
LikeLike
Perhaps it displays too much of a Protestant mindset, but I wouldn’t worry about the form, Barbara: it is the thought that counts. De Modo Orandi lists nine ways to pray, from holding your hands above your head, or in front, or to either side, to genuflection, flagellation, or prostration. Even reading (appropriate literature, naturally, and reflecting upon it – lectio divina) is a form of prayer.
In that light, contemplating images such as this painting, and thinking about it, with an appropriate frame of mind, is also a form of prayer. So thank you Richard 🙂
I suppose the most famous image of praying hands is the c.1508 drawing by Durer, which shows the fingers extended but as far as I can see the thumbs are not crossed. So the crossing of thumbs is clearly not universal. Indeed, I’d go so far as to say that more often than not a person depicted at prayer is shown with hands fingers and thumbs just held together. There are other examples with thumbs crossed, right over left, such as the Memling of a young man praying at the Thyssen-Bornemisza, but not in his pair of Portinari portraits. It is tempting to look for a little message here, but it may just be natural variation. Apologies for obsessing about this little detail.
LikeLike
I was taught by a nun to cross my thumbs when praying as part of preparation for my First Holy Communion (about age 7) but it may just have reflected the way that the nun made her own devotions. Any technique I had is now non-existent.
LikeLike
Thank you – it seems to be a fairly common experience, and so it’s odd that I’ve never come across it before!
LikeLike